

HTTP status codes are standardized responses used by web servers to tell you how your HTTP request was processed. They’re part of the HTTP (HyperText Transfer Protocol), which is essentially the foundation of data communication on the World Wide Web. These codes are part of the response from the server to the client (for example, your browser or a mobile app) after it has received and interpreted a request message.
Understanding HTTP status codes is crucial because they indicate whether your request was successful, if there was a problem, and what type of problem it might have been.
How HTTP codes work
Every time you click on a link or enter a URL, you’re essentially sending out a digital “request ticket” to the web server hosting the site you want to explore. This server then swings into action, processing your request. Once it’s deciphered what you’re after, it bundles up the necessary resources—be it web pages, images, or videos—along with an HTTP header, and sends this package back your way.
Within this HTTP header lies a digital nod or shake of the head from the server, known as the HTTP status code. These codes are the server’s succinct way of communicating with your browser, letting it know the outcome of your request. While your browser and the server are constantly exchanging these status codes, they usually do so behind the scenes.
However, when there’s a malfunction in this digital excjange—maybe the server can’t find the page you’re looking for or there’s an issue on its end—that these HTTP status codes are displayed on your browser window.
Take, for instance, the infamous Google 404 HTTP status code—a digital missing poster for the web page you were trying to find. It’s the server’s way of saying, “I looked everywhere, but I just can’t find what you’re looking for.”
If you’re curious to see these HTTP status codes that usually fly under the radar, there are numerous tools at your disposal. Browsers like Chrome and Firefox have extensions tailored for developers that show the HTTP status codes. You can also use web-based header fetching tools like Web Sniffer.
Using Google Search Console
Google Search Console (GSC) is an indispensable tool for webmasters and SEO professionals to understand how Google interacts with their sites. It offers insights into various aspects of your site’s performance in Google search, including the critical view of HTTP status codes through its Coverage report. This report is pivotal in monitoring and rectifying issues that could impact your site’s search engine visibility and user experience.
Understanding the Coverage Report
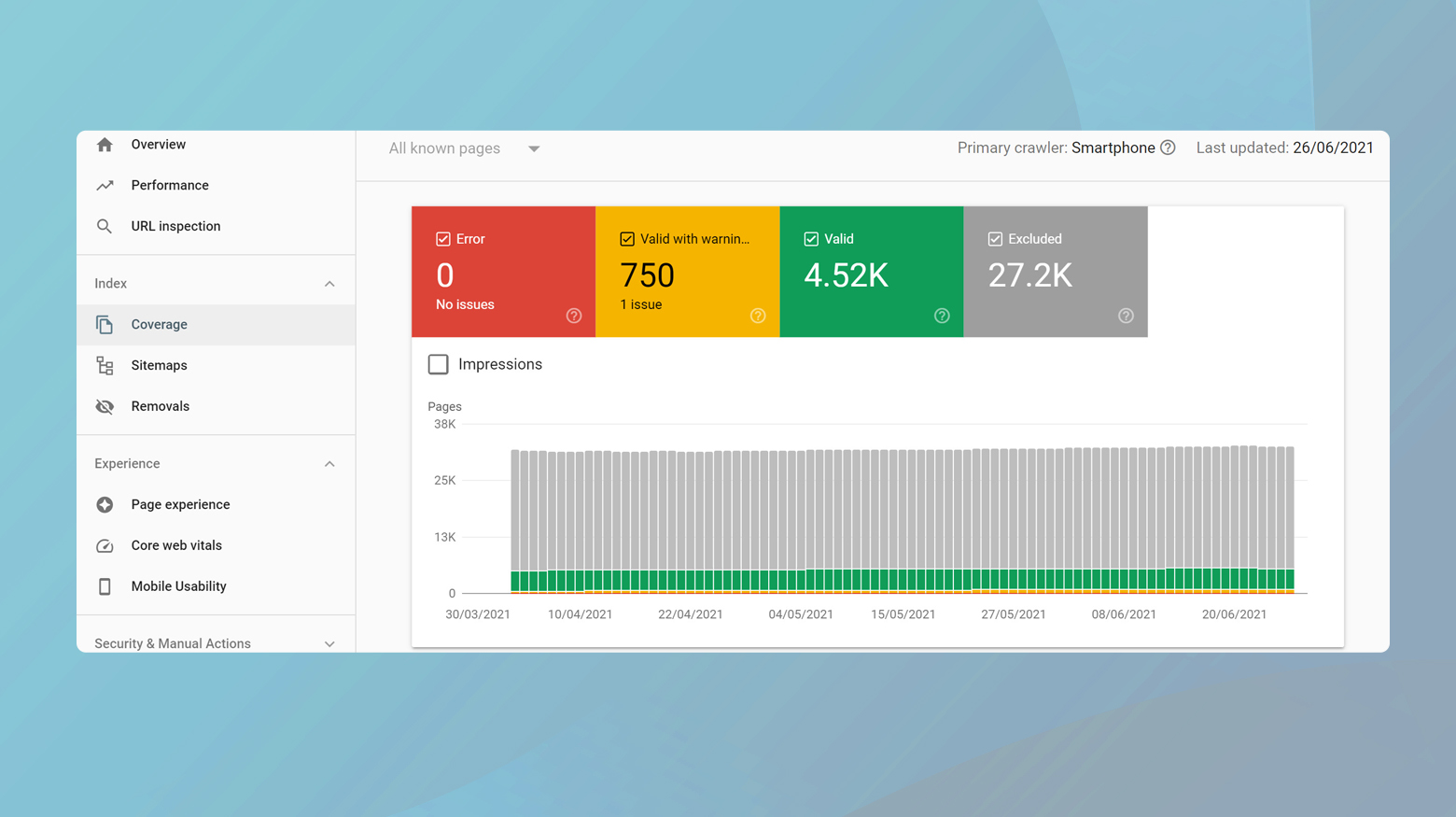
The Coverage report in Google Search Console classifies the content of your site into four main categories, providing a clear picture of how your site’s URLs are faring in Google’s eyes:
Errors: Pages that Google cannot index due to HTTP errors fall into this category. These could be due to 5xx server errors, which indicate server-side problems preventing Googlebot from accessing content, or 4xx client errors like 404 Not Found, signifying that the page does not exist.
Valid with warnings: This category is for pages that Google has indexed but identifies issues that might affect their performance or visibility. For example, a page that’s indexed but blocked by robots.txt might appear here.
Valid: URLs that have been successfully crawled and indexed without any issues are marked as valid. These pages are in good standing and are part of Google’s search index.
Excluded: This section includes URLs that Google decided not to index. This could include pages with 301 redirects, pages with canonical tags pointing to a different page, or duplicate content that Google chose not to index in favor of a more canonical version.
A particularly useful feature for SEO is the ability to identify pages with 300-level (redirection) status codes, like 301 Moved Permanently, which might be listed under Excluded as “Page with redirect.” This allows webmasters to review whether redirects are set up as intended or if unintentional redirects are potentially diluting SEO value by misdirecting link equity.
Using the URL inspection tool
For more granular insights into how individual URLs are being handled, the URL Inspection tool within GSC becomes invaluable. It allows you to pinpoint exactly why a specific page might be facing indexing issues. For instance, if Google is unable to index a page due to a 404 error, the URL Inspection tool will clearly display this status. This direct feedback can be instrumental in troubleshooting problems at the page level, ensuring that important content is not inadvertently excluded from Google’s index.
By leveraging these features within Google Search Console, webmasters can maintain a healthier website, ensuring that technical SEO issues, especially those related to HTTP status codes, are promptly identified and addressed. This proactive approach not only helps in optimizing your site’s presence in search results but also enhances the overall user experience by ensuring that visitors find the content they are looking for without running into dead ends or unnecessary redirects.
HTTP status codes and SEO
Search engine bots encounter HTTP status codes while crawling your website. These codes guide the bots in understanding the condition of your site’s pages. The relationship between these status codes and Search Engine Optimization (SEO) is nuanced, with some codes playing a more critical role than others.
The impact of 1xx and 2xx codes on SEO
HTTP status codes in the 100 and 200 range are like green lights on your website’s highway, signaling to search engine bots that everything is smooth sailing. These codes indicate that the request was received, understood, and processed correctly. From an SEO perspective, they’re neutral—while they don’t directly boost your rankings, they ensure that bots can access and index your content without a hitch, affirming the operational health of your site.
The SEO significance of 3xx codes
The 300-level codes are redirection codes and inform bots that a page has moved, but the nature of the move—temporary or permanent—matters greatly.
Permanent Redirects (301): 301s pass on most of the link equity (the SEO value transferred through links) from the original page to the new location. This means that if a page with a good number of high-quality backlinks moves, a 301 redirect helps retain its accumulated SEO value.
Temporary Redirects (302, 307): Temporary redirects signal a temporary move and do not pass link equity. If overused or incorrectly implemented, they can disrupt the flow of link equity throughout your site, potentially diluting the SEO value of your pages.
The SEO challenges of 4xx and 5xx codes
Encountering 400- and 500-level errors can prevent search engine bots from crawling and indexing your pages effectively.
4xx Errors (Client Errors): These codes indicate issues like missing pages (404 Not Found) or unauthorized access (403 Forbidden). Frequent 404 errors, for instance, can signal to search engines that your site is a ghost town with many dead ends, potentially harming your site’s perceived quality and usability.
5xx Errors (Server Errors): These signify server-side problems that make your site unreliable or inaccessible to both users and bots. A common example is the 500 Internal Server Error. If search engines frequently encounter these errors on your site, they might deem your site as unstable, which can negatively impact your rankings.
HTTP code types and definitions
HTTP status codes are categorized into five distinct classes. These classes are collections of responses that share similar or related implications. Understanding these classes can assist you in rapidly grasping the broad essence of a status code without needing to investigate its precise definition.
The five classes are comprised of:
1xx (Informational): Communicates transfer protocol-level information.
2xx (Successful): Indicates that the client’s request was successfully received, understood, and accepted. For example, 200 OK is the standard response for successful HTTP requests.
3xx (Redirection): Means further action must be taken by the client to complete the request. A common example is 301 Moved Permanently, which is used when a requested resource has been moved to a new URL permanently.
4xx (Client Error): These codes indicate an error that the client caused, such as 403 Forbidden, where access to the requested resource is denied.
5xx (Server Error): These codes indicate an error on the server’s side. For example, 503 Service Unavailable means the server is not ready to handle the request, often due to maintenance or being overloaded.
A comprehensive list of HTTP codes
1xx (Informational)
These status codes are provisional responses that acknowledge the request has been received by the server and the client should continue the request or ignore the response if the request is already finished. They’re rare in everyday web browsing because they deal with low-level protocol details that are typically handled by the HTTP client (your browser or app).
100 Continue: This tells the client that the initial part of the request has been received, and it should continue sending the rest of the request or ignore it if it’s already done.
101 Switching Protocols: The server understands and is willing to comply with the client’s request, via the Upgrade message header field, to switch protocols to those specified.
102 Processing (WebDAV): This code indicates that the server has received and is processing the request, but no response is available yet. This aims to prevent the client from timing out and assuming the request was lost.
103 Early Hints: This status code is primarily used to preload resources while the server is still preparing a response. It allows the client to load critical resources like stylesheets or images ahead of the final response.
2xx (Successful)
Indicates that the client’s request was successfully received, understood, and accepted. These status codes are the digital thumbs-up, indicating that the request has not only been received but also understood and accepted without an issue. Each code within this category provides a bit more specificity about how the server processed the request and what the outcome was. Below is a complete list of the 2xx status codes.
200 OK: This is the golden standard for HTTP responses. When you see this, it means your request was successfully processed in the most straightforward manner possible. If you sent a GET request, the server is returning the requested resource. For a POST request, this status could indicate that the submission was processed successfully.
201 Created: This code is a pat on the back for successfully creating something new on the server, typically in response to a POST request. It means not just that the request was accepted but that a new resource was born as a result of it. The response often includes a ‘Location’ header pointing to the newly created resource’s URI.
202 Accepted: Think of this as the server saying, “I’ve got your request, and it looks good, but I’m going to need some time to work on it.” It’s used for cases where the request has been accepted for processing, but the processing is not yet complete. It’s a way of acknowledging receipt in situations where a delay will follow.
203 Non-Authoritative Information: The server is a transforming proxy (e.g., a Web accelerator) that received a 200 OK from its origin, but is returning a modified version of the origin’s response.
204 No Content: This is the server’s way of saying, “I’ve successfully processed your request, but I don’t have anything to show for it.” It’s often used in response to a successful request that won’t result in a change to the displayed content, such as a successful delete operation or an update that doesn’t affect the current state of the client-visible resource.
205 Reset Content: The server successfully processed the request, but is not returning any content. Unlike a 204 response, this response requires that the requester reset the document view.
206 Partial Content: This status code is a bit more specialized, used when the server is fulfilling a partial GET request for a resource. It’s handy when large resources are requested, and the client wants to download it in chunks, like streaming a video or downloading a large file in segments.
207 Multi-Status (WebDAV): Provides status for multiple independent operations (for example, in a batch operation).
208 Already Reported (WebDAV): Used inside a DAV: propstat response element to avoid enumerating the internal members of multiple bindings to the same collection repeatedly.
226 IM Used (HTTP Delta encoding): The server has fulfilled a request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.
3xx (Redirection)
The 3xx class of HTTP status codes is all about redirection. These codes signal to the client that additional steps are necessary to complete the request. This could involve navigating to a different URL or perhaps automatically following a series of redirects until the final resource is reached. Here’s a closer look at the complete 3xx status codes.
301 Moved Permanently: This is the digital equivalent of leaving a forwarding address when you move homes.The response should include a ‘Location’ header specifying the resource’s new URL. Clients should update their links to this new address as the redirection is permanent.
302 Found ( Moved Temporarily): This status code is a bit more non-committal than a 301. It’s used when the resource has been temporarily moved to another URI. Clients should continue to use the original URI for future requests, as the redirection might change.
303 See Other: Think of this as a polite redirection, often used in response to POST requests. It tells the client to look at (GET) another URL and use a GET request for it, regardless of the original request method. This is useful for cases like submitting a form where you don’t want to resubmit the data if the user hits the refresh button.
304 Not Modified: This is a way to minimize unnecessary data transfer. It’s used when the client has performed a conditional GET request and access is allowed, but the document has not been modified since the version specified by the request’s If-Modified-Since or If-None-Match headers. In essence, it tells the client that the cached version of the requested resource is still good and can be used, saving bandwidth and speeding up web browsing.
305 Use Proxy (Deprecated): This response code was used to indicate that the requested resource must be accessed through the proxy given by the Location field. It has been deprecated due to security concerns regarding in-band configuration of a proxy.
306 Switch Proxy: This code was used in earlier specifications but is no longer used and is reserved for future use.
307 Temporary Redirect: This is similar to a 302 but with stricter adherence to the method used in the request. It means, “The resource you’re looking for is temporarily at this other URL, and you should use the same method (GET, POST, etc.) that you used originally to access it.”
308 Permanent Redirect: This is the newer, method-preserving counterpart to 301. It indicates that the resource has moved permanently to a new URL and future requests should use the new URL with the same method that was used in the original request.
4xx (Client Error)
The 4xx class of HTTP status codes marks the instances where something went wrong due to an issue on the client’s side. These codes are crucial for diagnosing user errors, misconfigurations, or unauthorized attempts to access resources. Let’s define all of the 4xx errors.
400 Bad Request: This is the HTTP equivalent of a blank stare in response to a confusing question. It’s used when the server cannot understand the request due to invalid syntax. It’s a general error response for when no other more specific code is appropriate. This can happen due to malformed request syntax, invalid request message parameters, or deceptive request routing.
401 Unauthorized: Despite the name, this status code actually means “unauthenticated.” It indicates that the request has not been applied because it lacks valid authentication credentials for the target resource. If you’re trying to access something that requires a login, and you haven’t logged in or your session has expired, you’re likely to encounter this response.
402 Payment Required: Reserved for future use. Initially intended for digital payment systems.
403 Forbidden: This code is about authorization rather than authentication. Even if you’re logged in, a 403 response means you’re trying to access a resource that you don’t have permission to see. It’s the server firmly saying, “I know who you are, but you still can’t come in here.”
404 Not Found: Perhaps the most well-known of all HTTP status codes, the 404 is the internet’s way of saying, “Nothing to see here.” It means that the server can’t find the requested resource. Links that lead nowhere – known as broken or dead links – are a common cause of this error.
405 Method Not Allowed: This response is given when the method specified in the request line is known by the server but has been disabled and cannot be used for the resource in question. For example, trying to POST to a URL that only accepts GET requests will result in this error.
406 Not Acceptable: The requested resource is capable of generating only content not acceptable according to the Accept headers sent in the request.
407 Proxy Authentication Required: Similar to 401 Unauthorized, but it indicates that the client must first authenticate itself with the proxy.
408 Request Timeout: Here, the server times out waiting for the request. This status is often returned when the client fails to send a request in the time that the server was prepared to wait. It’s the server’s way of saying, “I waited for you, but you took too long.”
409 Conflict: The request could not be processed because of conflict in the request, such as an edit conflict in the case of multiple updates.
410 Gone: The resource requested is no longer available and will not be available again.
411 Length Required: The request did not specify the length of its content, which is required by the requested resource.
412 Precondition Failed: The server does not meet one of the preconditions that the requester put on the request.
413 Payload Too Large: The request is larger than the server is willing or able to process.
414 URI Too Long: The URI provided was too long for the server to process.
415 Unsupported Media Type: The request entity has a media type which the server or resource does not support.
416 Range Not Satisfiable: The client has asked for a portion of the file, but the server cannot supply that portion.
417 Expectation Failed: The server cannot meet the requirements of the Expect request-header field.
418 I’m a teapot (April Fools’ joke in RFC 2324): This code was defined in 1998 as one of the traditional IETF April Fools’ jokes, in RFC 2324, Hyper Text Coffee Pot Control Protocol.
421 Misdirected Request: The request was directed at a server that is not able to produce a response (for example because a connection reuse).
422 Unprocessable Entity : The request was well-formed but was unable to be followed due to semantic errors.
423 Locked (WebDAV): The resource that is being accessed is locked.
424 Failed Dependency (WebDAV): The request failed because it depended on another request and that request failed.
426 Upgrade Required: The server refuses to perform the request using the current protocol but might be willing to do so after the client upgrades to a different protocol.
428 Precondition Required: The origin server requires the request to be conditional.
429 Too Many Requests: You’re being too eager! This response is issued when the user has sent too many requests in a given amount of time (“rate limiting”). It’s a measure to prevent abuse and ensure fair resource usage.
431 Request Header Fields Too Large: The server is unwilling to process the request because either an individual header field, or all the header fields collectively, are too large.
451 Unavailable For Legal Reasons: The server is denying access to the resource as a consequence of a legal demand.
499: Client Closed Request. NGINX returns this status code when the client terminates the request before NGINX has completed processing it.
5xx (Server Error)
The 5xx class of HTTP status codes indicates server errors, signifying that the server is aware it has encountered an error or is otherwise incapable of performing the request. Unlike 4xx codes, which signal client-side issues, 5xx errors imply problems on the server’s side that prevent it from fulfilling a valid request. Here’s a complete list of the 5xx HTTP status codes along with their detailed definitions.
500 Internal Server Error: This is a generic error message, given when an unexpected condition was encountered and no specific message is suitable. It’s the catch-all response for server-side issues that do not fit into any other category.
501 Not Implemented: The server either does not recognize the request method, or it lacks the ability to fulfill the request. Usually, this implies future availability (e.g., a new feature that is not supported yet).
502 Bad Gateway: This error occurs when the server, while acting as a gateway or proxy, received an invalid response from the upstream server it accessed in attempting to fulfill the request.
503 Service Unavailable: The server cannot handle the request (because it is overloaded or down for maintenance). Generally, this is a temporary state, and the server will specify how long the client should wait before retrying.
504 Gateway Timeout: The server, while acting as a gateway or proxy, did not receive a timely response from the upstream server or some other auxiliary server it needed to access in order to complete the request.
505 HTTP Version Not Supported: The server does not support the HTTP protocol version used in the request. This response is sent when the server refuses the use of the current HTTP version.
506 Variant Also Negotiates (Experimental): This code indicates that the server has an internal configuration error: the chosen variant resource is configured to engage in transparent content negotiation itself, and is therefore not a proper end point in the negotiation process.
507 Insufficient Storage (WebDAV): The server is unable to store the representation needed to complete the request. This status code is typically used when the server requires more storage space to fulfill the request.
508 Loop Detected (WebDAV): This status indicates that the server terminated an operation because it encountered an infinite loop while processing a request with “Depth: infinity”. This status indicates that the entire operation failed.
510 Not Extended: Further extensions to the request are required for the server to fulfill it. This status code is used in the RFC 2774 (An HTTP Extension Framework).
511 Network Authentication Required: This status code indicates that the client needs to authenticate to gain network access. It’s used by intercepting proxies that control access to the network (e.g., “captive portals” used to require agreement to Terms of Service before granting full Internet access via a Wi-Fi hotspot).
Closing thoughts
In this blog, we delved into HTTP status codes, covering their classifications (1xx, 2xx, 3xx, 4xx, 5xx) and their impact on web interactions and SEO. We discussed how certain codes, especially 3xx (redirection), 4xx (client error), and 5xx (server error), influence a site’s search engine ranking and indexing. We also explored the use of Google Search Console for monitoring these status codes, highlighting its Coverage report and URL Inspection tool as essential resources for identifying and addressing site issues related to these codes. The discussion emphasized the importance of properly managing HTTP status codes for website optimization and performance.
#1 Managed WordPress Hosting
Try 10Web for free, and enjoy all the benefits of a secure Google Cloud Partner hosting and 10Web's AI Website Builder.
Say goodbye to website errors
Fix all the website errors in one click
Migrate your website to the world's best Managed WordPress Hosting.







